CSV
- Michael Standal
- ken Halprin
- Imad Benariba (Deactivated)
Overview
The CSV output facilitates publishing collected records to comma-separated values files.
Configuration
See the General Object Configuration guide for assistance configuring the General tab.
CSV Tab
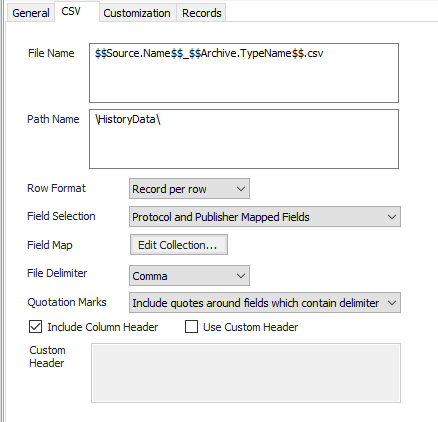
File Name
The name for the published file. The default is "$$Source.Name$$$$Archive.TypeName$$.csv"
Tokens
To select additional tokens, click in the edit box field to display the Property Specific option  in the tool bar, click on Property Specific and select the appropriate token under Insert Token Item.
in the tool bar, click on Property Specific and select the appropriate token under Insert Token Item.
The listing of available tokens and how they can be used is covered in the article called Substitution Tokens
Path Name
The destination for the published files. The default is "\HistoryData\CSV\ "
Row Format
- Record per row (Default). Combines complete history record on single row
Example:
Row 1 <Timestamp> <180.63><76.85>
Row 2 <Timestamp><198.75><79.00>
- Point per row. Create an individual row for each history point.
Example:
Row 1 <Timestamp> <Pressure><180.63>
Row 2 <Timestamp><Temperature><76.85>
Row 3 <Timestamp><Pressure><198.75>
Row 4 <Timestamp><Temperature><79.00>
- InSQL Fast Load. This format is accepted by Wonderware’s Historian.
- Clear SCADA CSV
Field Selection
Field Selection defines which fields in a historical record are included in the output of the publisher. Generally this includes all of the fields retrieved from the device when historical records were collected. This option and the "Field Map" option allow customization of that list to include more fields using information 'Tokens', or to reduce the number of fields by listing only the fields that are desired.
- Protocol and Publisher Mapped Fields . Combines both user defined and device fixed fields.(Default)
- Publisher Mapped Fields Only. Allow for only user defined history items to output with custom column names.
- Protocol Fields Only. Device fixed fields only.
Field Map
Field Map Data is where a Collection is entered. A collection provides a way to include additional fields in the output record, or to give existing fields a different column name.
Configure the Field Map Data by clicking Edit Collection...
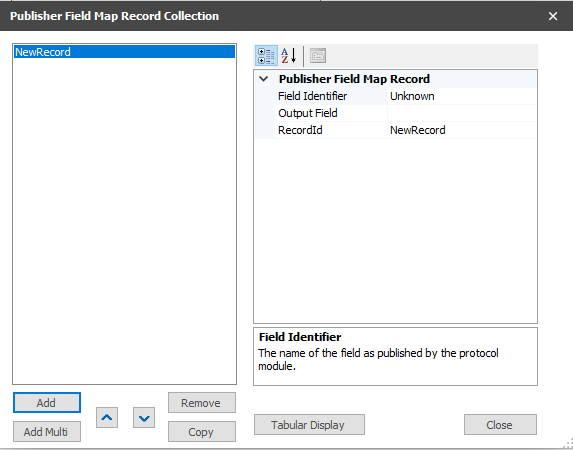
- Click Add to enter the appropriate number of New Record items
- Click Remove to delete any unwanted New Record items
- Click Tabular Display to view all New Record items at once
- Select the appropriate New Record item
- Click on Field Identifier. The name of the field as published by the protocol module. Select the identifier from the Selection form when the edit icon is selected.
- Click on Output Field. Enter the appropriate name or leave blank.
- Click on Record ID and enter the appropriate name.
- Click Close to leave dialog
File Delimiter
Select the desired file delimiter to use.
- Comma (Default)
- Tab
- Pipe
- Colon
Quotation Marks
This option may be necessary when the data is likely to contain the Microsoft Excel default delimiter (the comma). Using this option will cause the publisher to surround data with quotes. This will assist Microsoft Excel in interpreting the difference between commas meant to delimit and commas meant to be in the data.
Quote options can be configured to:
- Do not include quotes around fields
- Include quotes around all fields
- Include quotes around fields which contain delimiter (the comma) (Default)
Include Column Header
Default = Selected.
Use Custom Header
Default = Not selected. Use Custom Header in CSV file.
Customer Header
If "Use Custom Header" is selected, fill in the desired header for the published CSV.
Customization Tab
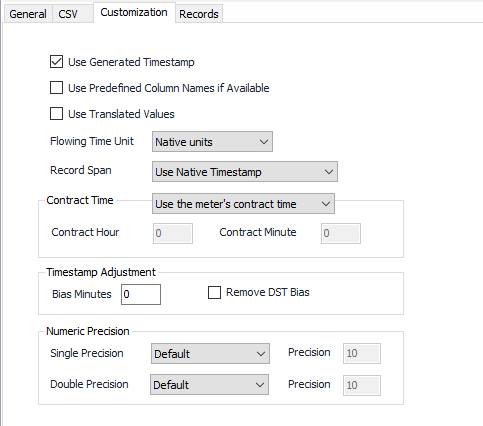
Use Generated Timestamp
Default = Selected. Include the record timestamp in the published output. (Some protocols may also provide a timestamp as a field in the record).
Use Predefined Column Names if Available
Default = Not selected. Select to use predefined column names if available, otherwise use names provided by the protocol driver.
Use Translated Values
Default = Not selected. Select to use EFM Translated values for fields instead of the raw value from the protocol. Example: Turbine instead of 0.
Flowing Time Unit
Select the desired units for the Flowing Time value.
- Native Units (Default)
- Seconds
- Minutes
- Hours
Record Span
This setting determines whether timestamps are left as provided by the flow computer or all records are converted to leading time stamps.
- Use Native Timestamp (Default)
- Convert to Leading Timestamp
Contract Time
- Do not use contract time.
- Use the configured contract time. Enter the appropriate Contract Hour and Minute.
- Use the meter’s contract time (Default). Uses defined contract time per the Protocol or Meter object.
Timestamp Adjustment
Bias Minutes
The number of minutes to apply to the record time stamp. e.g. CST to GMT = 360, CST to Mountain = -60. Default is 0.
Remove DST Bias
Default = Not selected. Remove the DST bias from record stamps that fall within Daylight Savings Time. Only do this if the source records follow Daylight Savings Time.
Single Precision
Default = Default. Select Custom to enter a value for Precision. See Numeric Precision.
Double Precision
Default = Default. Select Custom to enter a value for Precision if Custom is selected. See Numeric Precision.
Records Tab

History Period Time
Select the time period of the record types to be written to the file.
- All (Default)
- Hourly
- Daily
- Other
Period Time
Default = 60 (minutes). If "Other" is selected above, the publisher will use this value to publish only those records that have a matching period value.
Check all required record types to be published.
How To
Add an empty column to a published csv file
- Create a String object in ACM or identify any existing String object that can be used as a column place-holder.
- Use any desired option other than "Protocol Fields Only" for the Field Selection on the CSV tab.
- Use the “Edit Collection” button to edit the custom field collection.
- Click the “Add” button to add a new entry to the collection.
- In the new entry that appears, open the Field Identifier selector (the “…” button) and choose the string object that was identified earlier. Note: If the CSV output object is publishing a record that already contains a value for the selected String object, the field's value will be used. To put an empty column into a csv file, the String object cannot be referenced by any device history records.
- Type the desired name for the column in the “Output Field”.
- Save and close the collection editor and save the CSV output object. The next time the CSV output object creates a new file to publish data, the file will contain the new column with an empty value for that column in every row.
Add a constant value to every row in a specific column in a published csv file
- Create a String object in ACM or identify any existing String object that can be used as a column place-holder.
- Use any desired option other than "Protocol Fields Only" for the Field Selection on the CSV tab.
- Use the “Edit Collection” button to edit the custom field collection.
- Click the “Add” button to add a new entry to the collection.
- In the new entry that appears, open the Field Identifier selector (the “…” button) and choose the string object that was identified earlier.
- Type the desired name for the column in the “Output Field”, enclosing the name in double quotes. Then add an equal sign, followed by the constant field value enclosed in double quotes. For example, to produce a column named “Color” that has the value “Red” in every row, the Output Field should look like this: “Color”=”Red”.
- Save and close the collection editor and save the CSV output object. The next time the CSV output object creates a new file to publish data, the file will contain the new column with the constant value for that column in every row.
Use a field’s value as part of the file name in a published csv file
- Use the token “$$FieldN$$ in the “File Name” box where the value should appear. Replace the “N” in “$$FieldN$$” with the one-based index number of the field whose value should be used.
- Save the CSV output object. The next time the CSV output object creates a new file to publish data, it will find the field at index 'N' in the record and use that field's data to substitute for the token string in the file name.
Related content
For assistance, please submit a ticket via our Support Portal, email autosol.support@autosoln.com or call 281.286.6017 to speak to a support team member.